Hacking ani-cli
ani-cli is designed to scrape a single platform—currently AllAnime. Supporting multiple sources would require significant changes, so feature requests for new sites are generally rejected.
However, since ani-cli is open-source and many anime streaming sites are similar, you can modify it to support any site that follows a few common conventions.
Prerequisites
This guide assumes you have the following skills:
- Basic shell scripting
- Understanding of HTTP(S) requests and proficiency with
curl - Ability to read HTML and JavaScript at a basic level
- Experience writing regular expressions (regex)
You will also need a web browser with a debugger and an environment that can run an unmodified ani-cli.
The Scraping Process
The following flowchart demonstrates how ani-cli operates from a scraping standpoint:
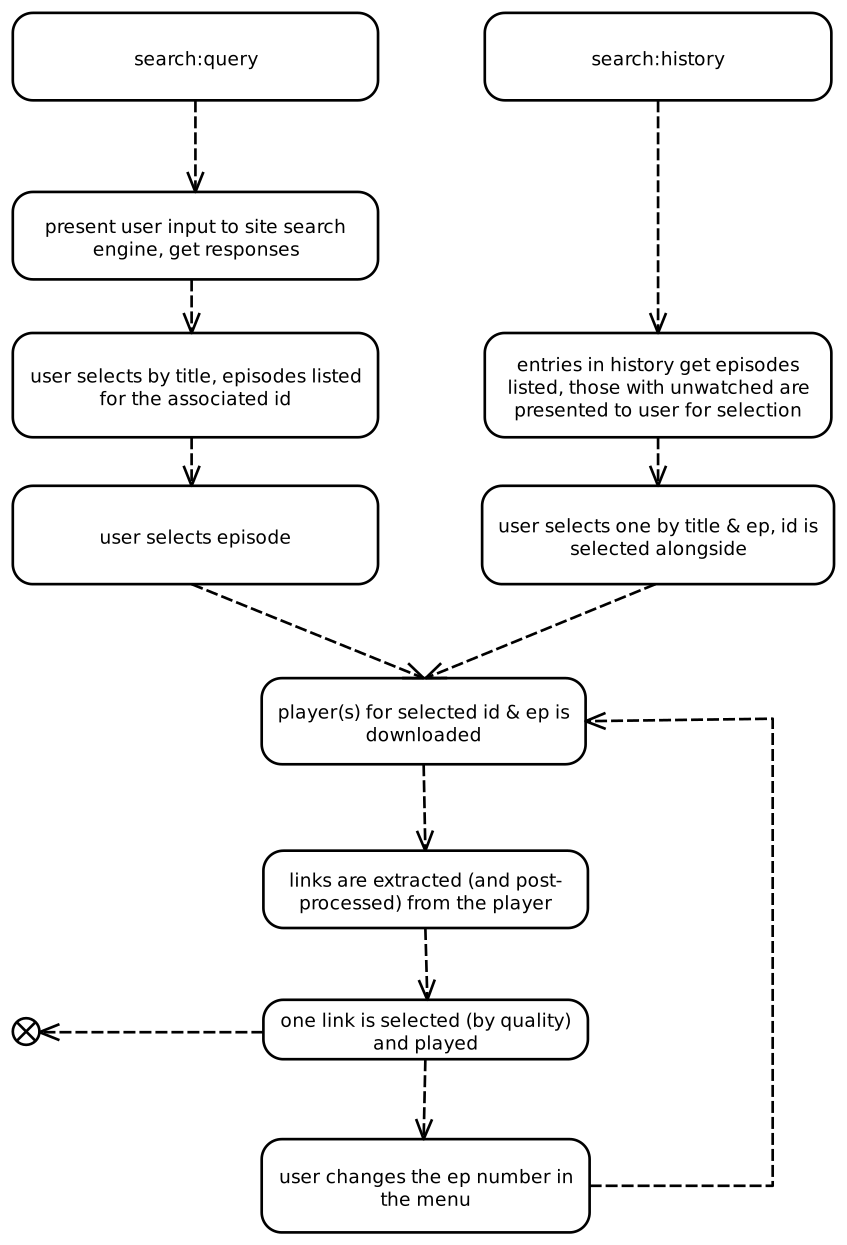
The steps to get a video link from a query are:
- Search the site with the user's query.
- Extract IDs and titles from the response; user chooses one.
- Extract episode numbers from an overview page; user chooses one.
- Download the player/embed URLs for the chosen episode and extract direct video links.
- The user's quality selection determines which link is played.
To support another site, you will need to modify steps 1-4.
Reverse-Engineering
Many sites have protections against reverse-engineering. Browser extensions like webapi-blocker can help with using the debugger. These protections are constantly evolving, so you may need to do your own research to bypass them.
Core Concepts
On most streaming sites, an anime episode is represented by a URL containing a series ID and an episode number. In ani-cli, the series identifier is stored in the id variable and the episode number in ep_no.
Each episode page has an embedded player that contains the direct links to video files. Your goal is to extract these links along with their corresponding resolutions (quality).
1. Searching
Find the site's search functionality. Most sites use a simple GET request where the query is part of the URL. If it's more complex (like a POST request), use your browser's debugger to analyze the network traffic.
Once you understand how searching works, replicate it in the search_anime function in the ani-cli script. The curl command makes the request, and the subsequent sed commands format the response into lines of id\ttitle.
2. Episode Selection
Next, you need to get a list of all available episodes for a selected series. This is handled by the episodes_list function. You'll need to find the series overview page and write a curl command and sed regexes to extract a newline-separated list of episode numbers.
3. Getting the Player Embed
After an episode is selected, you need to load its page and extract the URL for the embedded video player. In the script, this logic starts around the comment get the embed urls of the selected episode. The goal is to populate the resp variable with lines in the format sourcename : url.
Some sites may obfuscate these URLs. You may need to adapt or remove the existing decryption logic.
4. Extracting the Media Links
Finally, you need to parse the embed player's content to get the direct media links. This is done in the get_links function.
Request the embed URL and extract links into the format quality > link. The quality should be a numeric representation of the resolution (e.g., 1080p). The output of this function is then used for the final quality selection process.
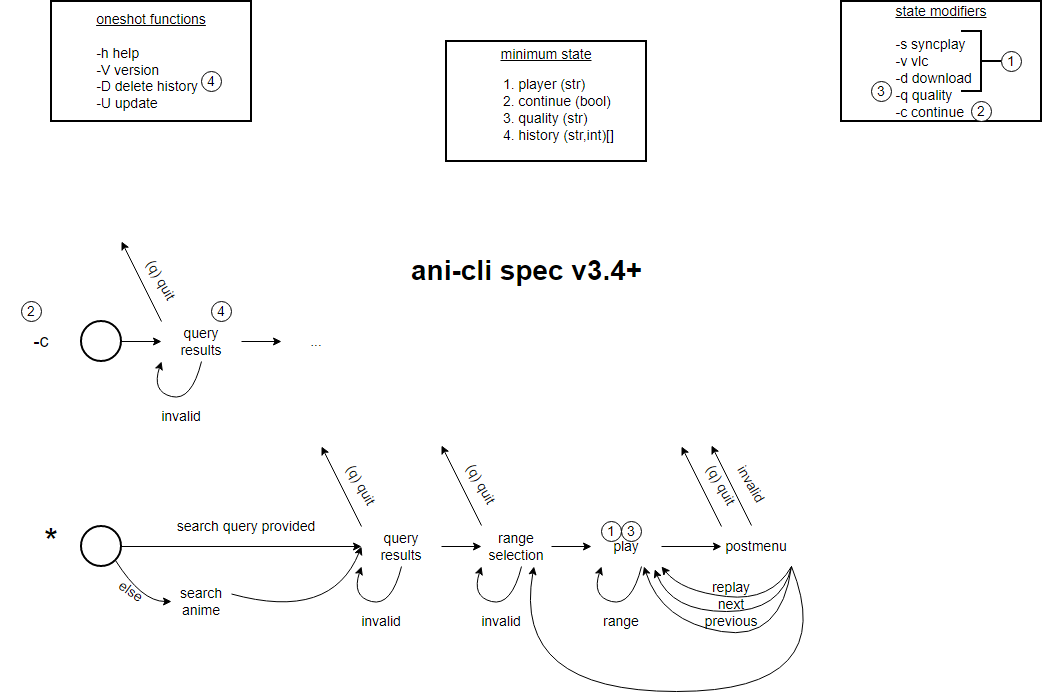
UX Spec
If you are building a new client from scratch and want to replicate the ani-cli user experience, you can refer to this UX specification: